October 29th, 2025
Announcement

Three years ago, Extropic made the bet that energy would become the limiting factor for AI scaling.
We were right.[0]
Scaling AI will require a major breakthrough in either energy production, or the energy efficiency of AI hardware and algorithms.
We are proud to unveil our breakthrough AI algorithms and hardware, which can run generative AI workloads using radically less energy than deep learning algorithms running on GPUs.
To explain our work, we are releasing:
thrml, our Python library for simulating our hardware, which can be used to develop thermodynamic machine learning algorithmsWith the fundamental science done, we are moving from breakthrough to buildout.
Once we succeed, energy constraints will no longer limit AI scaling.
Like other AI companies, we envision a future where AI is abundant. We believe AI is a fundamental driver of civilizational progress, thus scaling AI is of paramount importance. We imagine a future where AI helps humanity discover new drugs to cure disease, predicts the weather better to mitigate the impact of natural disasters, improves automation of manufacturing, drives our cars, and augments human cognition in a democratized fashion. We hope to bring that future to reality.
However, that future is completely out of reach with today’s technology. Already, almost every single new data center is experiencing difficulties sourcing power[0]. With today’s technology, serving advanced models to everyone all the time would consume vastly more energy than humanity can produce. To provide more AI per person, we will need to produce more energy per person, or get more AI per Joule.

Continuing to scale using existing AI systems will require vast amounts of energy. Many companies are working on better ways to produce that energy, but that is only half of the equation.
Extropic is working on the other half of the equation: making computing more efficient. Scaling up energy production requires the support of a nation-state, but a more efficient computer can be built by a dozen people in a garage outside Boston.
If we constrain ourselves to the computer architectures that are popular today, reducing energy consumption will be very hard. Most of the energy budget in a CPU or GPU goes towards communication, because moving bits of information around a chip requires charging up wires. The cost of this communication can be reduced by either reducing the capacitance of the wires or reducing the voltage level used for signalling. Neither of these quantities has gotten significantly smaller over the last decade, and we don’t think they will get smaller in the next decade either.
Fortunately, we don’t need to limit ourselves to today’s computer architectures. Today’s AI algorithms were designed to run well on GPUs because GPUs were already popular, but GPUs only became popular because they were good at rendering graphics. GPUs can do amazing things, but today’s machine learning paradigm is the result of evolution, not design.
Progress in deep learning research fuels progress in GPU design, and vice-versa.
The current machine learning paradigm has a lot of momentum. Without a major shift in computing demand, there’s no reason to throw away decades of optimizations to start over from scratch.
But recently, computational demands have shifted from deterministic to probabilistic, and from performance-constrained to energy-constrained.
To meet those demands, Extropic has developed a new type of computing hardware for the probabilistic, energy-efficient, AI-powered future.
We have developed a new type of computing hardware, the thermodynamic sampling unit (TSU).
We call our new hardware a sampling unit, not a processing unit, because TSUs perform an entirely different type of operation than CPUs and GPUs. Instead of processing a series of programmable deterministic computations, TSUs produce samples from a programmable distribution.
Running a generative AI algorithm fundamentally comes down to sampling from some complicated probability distribution. Modern AI systems do a lot of matrix multiplication to produce a vector of probabilities, and then sample from that. Our hardware skips the matrix multiplication and directly samples from complex probability distributions.
Specifically, TSUs sample from energy-based models, which are a type of machine learning model that directly define the shape of a probability distribution via an energy function.
The inputs to a TSU are parameters that specify the energy function of an EBM, and the outputs of a TSU are samples from the defined EBM. To use a TSU for machine learning, we fit the parameters of the energy function so that the EBM running on the TSU is a good model of some real-world data.
TSUs are made up of massive arrays of sampling cores.
TSUs leverage these cores to sample from EBMs by compiling them down to simpler operations using the Gibbs sampling algorithm.
Gibbs sampling is an iterative algorithm which performs a small number of simple and fast operations to sample from large and complex energy-based models[0]. Generally, TSUs enable sampling from Probabilistic Graphical Models (PGMs) [0] made of EBMs.
A TSU can combine many simple probabilistic circuits to sample from more complex distributions.
TSUs have a very different architecture than GPUs. Instead of having separate memory and compute circuitry, TSUs store and process information in a completely distributed manner where communication only happens between circuits that are physically close to one another. This minimizes the amount of energy spent on communication.
This emphasis on local communication, along with our novel probabilistic circuit design, allows our TSUs to be extremely energy efficient.
You can find a more in-depth explanation of the architecture of TSUs here, or run simulations of TSUs using
thrml.
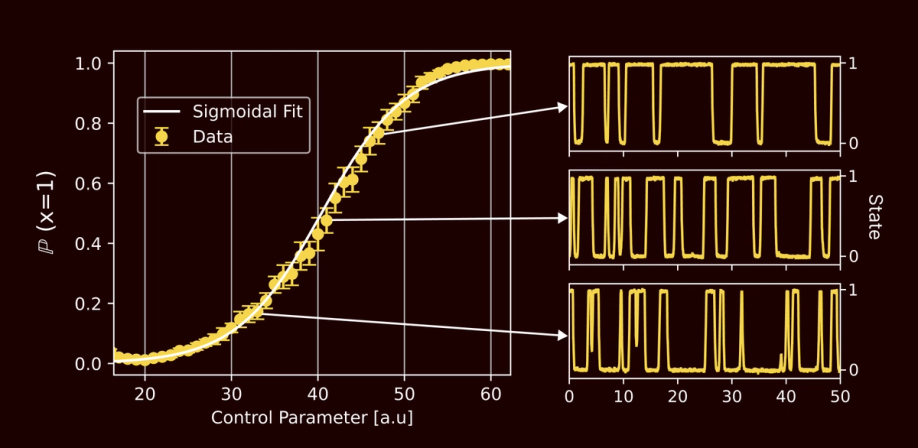
Our first generation TSUs are made up of a large network of pbits. Pbits output a voltage that randomly wanders between two states, which are interpreted as a 1 or a 0. The probability of finding the output signal in either state at any given time is programmable, which allows the pbit to be used as a source of samples from a Bernoulli distribution.
By varying a control voltage, the random voltage signal coming out of a pbit can be tuned spend more time in the 1 state than the 0 state, or vice versa.
A pbit is just a random number generator. But we can combine many pbits together into a much more sophisticated TSU, by having each pbit’s probability be determined by the sum of a bias and the weighted sum of that pbit’s neighbors’ values. We explain this process in detail in our post about the TSU architecture.
Much like a single NAND gate, a single pbit may seem trivial. But just as huge numbers of NAND gates can be combined to make a CPU that can run Google Chrome, huge numbers of pbits can be combined to make a TSU that can sample from a useful probability distribution.
Academics have proposed many designs for pbits, but those designs are not commercially viable because they rely on exotic components or unproven fabrication processes.
To build a better pbit, we spent years developing new models of noise in electronic circuits. With these models, we were able to design a new type of pbit, which uses orders of magnitude less energy to generate randomness than existing implementations. To validate our design, we manufactured a hardware proof of technology, which proved that our pbit design works in practice.
Our pbits are energy-efficient, small, and made entirely of transistors. Because they are energy-efficient and small, we can combine many of them to build an efficient and compact TSU. And because our pbits are made entirely of transistors, they can be easily integrated with the rest of the circuits you need to make a full TSU.
To demonstrate how our hardware can be used for AI, we invented a new generative AI model, the Denoising Thermodynamic Model (DTM).
DTMs were inspired by diffusion models, and leverage TSUs to generate data by gradually pulling that data out of noise over several steps. You can find an explanation of how DTMs run on TSUs here.
Running DTMs on our TSUs could be 10,000x more energy efficient than modern algorithms running on GPUs, as shown by our simulations of TSUs running DTMs on the small benchmarks in our paper.
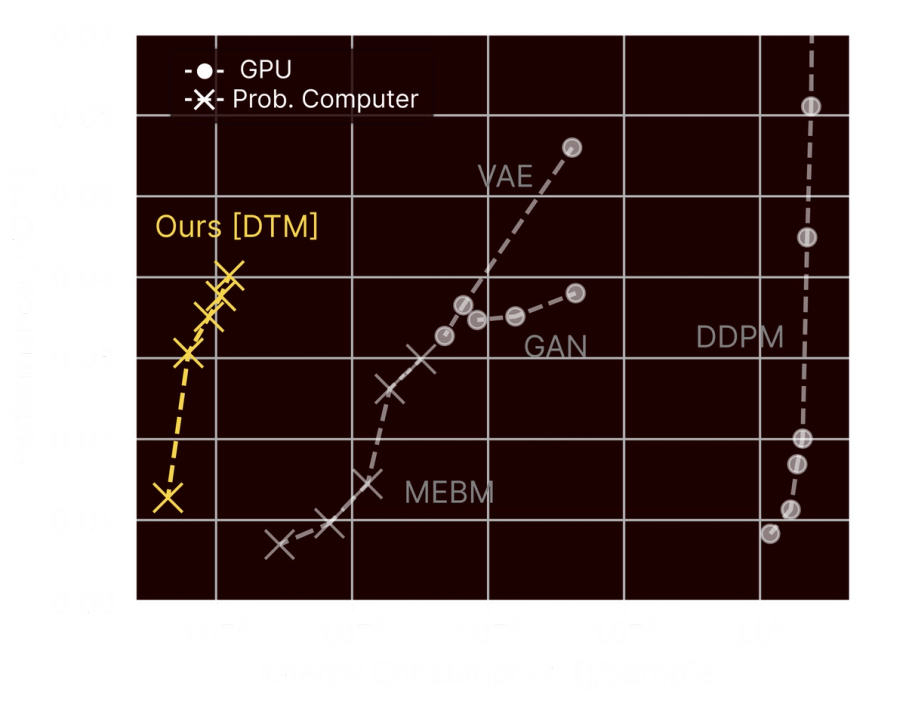
In our paper, we showed that simulations of small sections of our first production-scale TSUs could run small-scale generative AI benchmarks using far less energy than GPUs.
This work on DTMs is the first glimpse of what machine learning workloads can look like on TSUs. We believe that DTM’s will start a thermodynamic machine learning revolution, inspiring AI researchers to explore novel architectures and algorithms made for TSU’s in order to achieve unparalleled AI performance per watt.
The library that we used to write our simulations, thrml, is now open source. Using thrml, the open-source community can start developing algorithms for TSUs before the hardware becomes commercially available.
We funded an independent researcher to replicate our paper using the latest version of thrml, and that replication is now open-source. Anyone with a GPU can replicate the results from our paper by running that code.
Our mission is to remove the energy constraints that currently limit AI scaling.
To accomplish that mission, we will need to dramatically scale up the capabilities of our hardware and algorithms.
While we have accomplished a lot so far with our small team, we are going to need more help to build production-scale systems.
We are looking for experienced mixed signal integrated circuit designers and hardware systems engineers to help us build progressively larger computers that can power more and more of the world’s AI inference.
We are also seeking experts in probabilistic ML to enhance the capabilities of our algorithms to match those of today's foundation models, both by developing algorithms that run solely on a TSU and by developing hybrid algorithms that leverage both TSUs and GPUs.
We intend to use TSUs for tasks other than running AI models, such as simulations of biology and chemistry. We are hoping to develop partnerships with organizations that run probabilistic workloads, to develop new algorithms that will enable them to leverage our next generation chips. If this sounds interesting to you, fill out our algorithmic partnership form.
We invite early-career researchers and PhD students who are interested in the theory and application of TSUs to apply for a research grant.